This guide provides technical details for deploying VMware ESXi and VMware vSphere on Blockbridge iSCSI storage.
Most readers will want to start with the Deployment and Tuning Quickstart section. It’s an ordered list of configuration and tuning steps, and it’s the fastest path to an optimal installation. The rest of the document provides detail on all aspects of using VMware with Blockbridge:
-
Deployment Planning is a discussion of how to plan your VMFS datastores for performance and flexibility. It describes how best to configure VMware’s Storage I/O Control and Storage Distributed Resource Scheduler features for use with all-flash storage.
-
Networking & Storage provides administration, provisioning, and configuration details. The bulk of the content is devoted to networking requirements for multipath storage access. Additional topics include how to provision storage with Blockbridge and how to connect it to your ESXi hosts.
-
Host Tuning enumerates recommendations for host-level ESXi parameters that affect the performance, features, and resiliency of iSCSI storage.
-
Guest Tuning offers additional recommendations for achieving high performance from guest VMs.
DEPLOYMENT & TUNING QUICKSTART
This is a quick reference for configuring and tuning VMware backed by Blockbridge storage. For the most trouble-free installation, configure your networking first. Then, provision and attach the storage. We recommend working through the installation in this order:
- Configure VMware for iSCSI networking.
- Provision Blockbridge storage and configure it for secure access.
- Attach the storage to VMware, then tune it.
- Create a VMFS-6 datastore.
- Confirm VMware system settings.
Many of these topics have more information available by selecting the information ⓘ links next to items where they appear.
VMware iSCSI Networking
-
Configure VMware networking and the VMware iSCSI adapter to support multiple storage paths. ⓘ
- If your network interface ports are on the same subnet, create iSCSI Port Bindings.
- If your network interface ports are on different subnets, no additional virtual networking is required.
-
Configure Jumbo Frames as needed. ⓘ
-
Increase the iSCSI LUN Queue Depth. ⓘ
- For a small population of ESXi hosts, increase LunQDepth to 192 for maximum IOPS.
- Otherwise, default settings are appropriate.
esxcli system module parameters set -m iscsi_vmk -p iscsivmk_LunQDepth=192 -
Increase the iSCSI Login Timeout to ride out LUN failovers. ⓘ
esxcli iscsi adapter param set --adapter=vmhba64 --key=LoginTimeout --value=60 -
Increase the Large Receive Offload Maximum Length. ⓘ
esxcfg-advcfg -s 65535 /Net/VmxnetLROMaxLength -
Verify that NIC Interrupt Balancing is Enabled. ⓘ
esxcli system settings kernel list | grep intrBalancingEnabled intrBalancingEnabled Bool true ... -
Apply Mellanox ConnectX-3 NIC Tuning. ⓘ
- Repeat for each interface port.
esxcli network nic ring current set -r 4096 -n vmnicX esxcli network nic coalesce set -a false -n vmnicX esxcli network nic coalesce set --tx-usecs=0 --rx-usecs=3 --adaptive-rx=false -n vmnicX -
Apply Mellanox ConnectX-4,5+ NIC Tuning. ⓘ
- Repeat for each interface port.
esxcli network nic ring current set -r 4096 -n vmnicX esxcli network nic coalesce set --tx-usecs=0 --adaptive-rx=true -n vmnicX
Blockbridge Virtual Storage
-
Create a global iSCSI initiator profile.
- Register the iSCSI qualified name (IQN) of each VMware iSCSI adapter.
- Configure CHAP authentication credentials.
bb profile create --label 'cluster profile' --initiator-login 'esx' --initiator-pass ************ bb profile initiator add --profile 'cluster profile' --iqn iqn.1998-01.com.vmware:bb-cluster-4-0b2f0b43 -
Provision a virtual storage service.
- We recommend a single VMware datastore per Blockbridge complex for optimal performance.
- Create the storage service from the “system” account on the Blockbridge GUI to guarantee datastore placement.
-
Create a virtual disk within the virtual service.
- We recommend a single Blockbridge virtual disk per VMware datastore.
bb disk create --vss cx1:nvme --label ds1 --capacity 1TiB -
Create an iSCSI target within the virtual service.
- Add a LUN mapping for your virtual disk.
- Insert your global iSCSI initiator profile into the access control list.
bb target create --vss cx1:nvme --label target1 bb target acl add --target target1 --profile cluster-profile bb target lun map --target target1 --disk ds1
VMware Storage Devices
-
Add a Dynamic Discovery Target.
- Choose one of the Blockbridge target portals - VMware will find the others.
esxcli iscsi adapter discovery sendtarget add --adapter=vmhba64 --address=172.16.200.44:3260 -
Increase the SchedNumReqOutstanding Depth for each storage device. ⓘ
esxcli storage core device set --sched-num-req-outstanding=192 \ --device=naa.60a010a0b139fa8b1962194c406263ad -
Set the Round-Robin path selection policy for each storage device. ⓘ
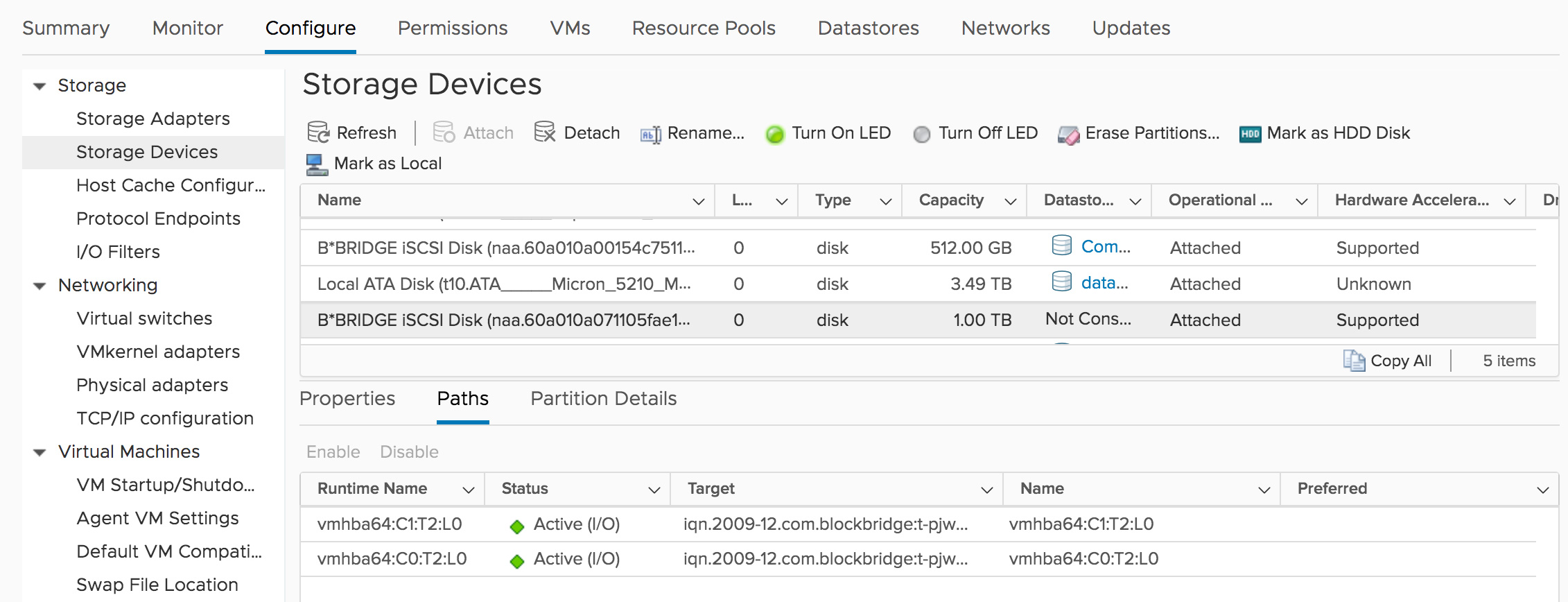
esxcli storage nmp device set --psp=VMW_PSP_RR --device=naa.60a010a071105fae1962194c40626ca8 -
Lower the Round Robin Path Selection IOPS Limit for each storage device. ⓘ
esxcli storage nmp psp roundrobin deviceconfig set --type=iops --iops=8 \ --device=naa.60a010a03ff1bb511962194c40626cd1 -
Selectively enable Queue Depth Throttling. ⓘ
For a small population of ESXi hosts:
- Confirm that Queue Full Sample Size is 0.
esxcli storage core device list | grep 'Queue Full' Queue Full Sample Size: 0 Queue Full Threshold: 0 Queue Full Sample Size: 0 Queue Full Threshold: 0For a large population of ESXi hosts:
- Enable Adaptive Queue Throttling.
esxcli storage core device set --device device_name --queue-full-sample-size 32 --queue-full-threshold 128 -
Use this bash script helper to apply esxcli commands to all devices.
for dev in $(esxcli storage nmp device list | egrep ^naa); do esxcli ... --device=${dev} done
VMware Datastore & VMFS
-
Create a VMware datastore for each Blockbridge disk. ⓘ
- Use VMFS version 6 or higher.
VMware System Settings
Optionally, validate that the following system-wide settings retain their default values.
-
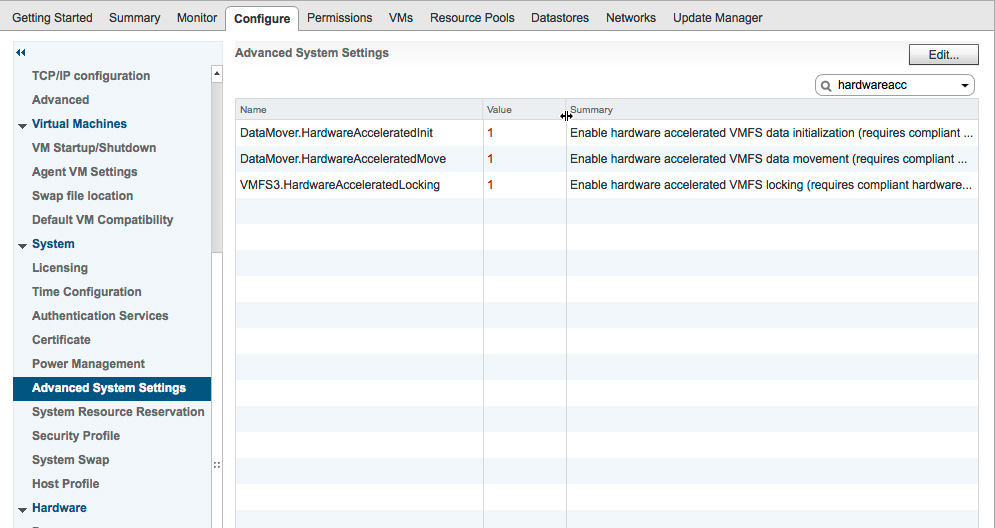
Confirm that VAAI Commands are Enabled. ⓘ
esxcli system settings advanced list -o /VMFS3/HardwareAcceleratedLocking ... Int Value: 1 esxcli system settings advanced list -o /DataMover/HardwareAcceleratedMove ... Int Value: 1 esxcli system settings advanced list -o /DataMover/HardwareAcceleratedInit ... Int Value: 1 -
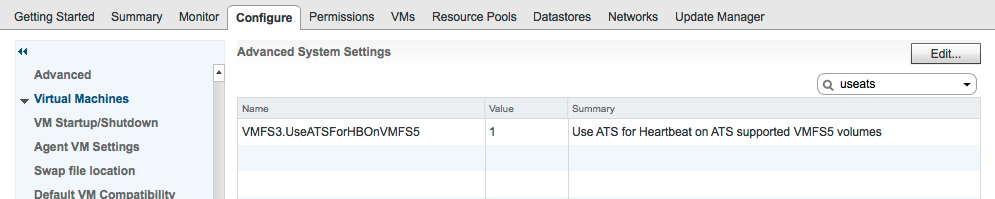
Confirm that the SCSI “Atomic Test and Set” Command is Used. ⓘ
esxcli system settings advanced list -o /VMFS3/UseATSForHBOnVMFS5 ... Int Value: 1 -
Confirm that VMs are Halted on Out of Space Conditions. ⓘ
- This option should be disabled.
esxcli system settings advanced list -o /Disk/ReturnCCForNoSpace ... Int Value: 0
DEPLOYMENT PLANNING
Datastores, Complexes & LUNS
Historically, VMware’s storage performance is entirely limited by the backend array. In days of HDD and hybrid HDD/SSD storage systems, many administrators used a large number of low capacity LUNs to improve performance. The performance improvement was attributed to a better distribution of I/O across high-latency media.
With All-SSD and All-NVMe arrays, VMware’s iSCSI initiator is likely the primary performance bottleneck, especially for high-IOPS workloads. When operating an ESXi host in the range of hundreds of thousands of IOPS, you’ll see a significant rise in CPU utilization and NIC interrupt processing overhead. One of the best ways to ensure consistent storage performance is to have adequate CPU resources available for the storage subsystem. You may also unlock additional initiator-side concurrency benefits by doubling up on the number of VMFS datastores you build from a Blockbridge dataplane complex. While it’s not a guaranteed win, it may be worth an experiment if you are equipped with high-performance servers.
We do not recommend incorporating multiple LUNs into a single datastore. VMFS extents are not stripes. You are not likely to realize any additional performance with multiple extents. Plus, Storage I/O Control will not work on datastores with multiple extents.
For Storage DRS, using a greater number of smaller LUNs can give VMware’s algorithm more leeway to achieve a balanced performance and capacity solution. However, making the datastores too small could force additional vMotions and create dead spaces that aren’t easily recaptured. It’s best to avoid slicing and dicing the storage too thinly.
VMware Storage Limits
When planning your installation, keep in mind the following limits for VMFS6 as of vSphere 6.5:
| Parameter | Limit |
|---|---|
| Maximum iSCSI LUNs | 512 |
| Maximum software iSCSI targets | 256 |
| Maximum volume size | 64 TB |
| Concurrent vMotion ops per volume | 128 |
| Powered on VMs per volume | 2048 |
Storage I/O Control
Storage I/O Control (SIOC) is VMware’s solution to the “noisy neighbor” problem: when a single VM’s I/O load swamps the storage subsystem, negatively affecting the performance of other VMs. SIOC allows the hypervisor to throttle guest I/O when the latency or throughput of the storage subsystem increases beyond a predefined point. You can specify policies for how each guest’s I/O is scheduled when SIOC is active.
Blockbridge dataplanes fully support SIOC, as all of the enforcement is performed in the ESXi host. If raw, global performance is your primary concern, you should leave SIOC disabled. The best performance is going to happen when VMware can issue I/O’s out to the LUN as quickly as possible. However, if you have VMs that require predictable I/O latency, you may find that SIOC helps meet those requirements.
Correctly implementing SIOC starts with understanding exactly where it sits in the ESXi I/O stack:

Source: Troubleshooting Storage Performance in vSphere Part 5: Storage Queues (VMware)
In the above diagram, the SIOC measurement point is on top of the Driver. It measures the round-trip latency and throughput of I/O’s issued to the device queue. With a Blockbridge iSCSI LUN, this is the time between when ESXi hands off the I/O to its iSCSI initiator and when it receives the response. DQLEN, shown above, counts I/O’s that are in this state. When SIOC measures I/O performance, it’s measuring the performance at the iSCSI LUN from this point of view, not any latency related to queueing on the ESXi host or the world queue above the device in the I/O stack.
When this latency gets too long, or when the throughput gets too high, SIOC shortens the device queue and starts enforcing the configured I/O shares assigned to each VM. This backs up the I/O load into the World queue, trading off increasing latency for more fairly managed storage. However, a major downside of SIOC’s approach is that it reduces the effectiveness of the backing storage by shortening the device queue.
Should you use SIOC, go with the default setting of triggering SIOC at a percentage (default 90%) of maximum throughput. The minimum “manual” latency threshold is 5ms, which is quite a long time for an all-flash array, even with a full queue.
SIOC is useful when it functions as an escape valve. When properly implemented, it shouldn’t kick in most of the time, only responding to periods of truly intense workloads with tighter regulation of guest I/O. But its action to reduce the device queue depth also reduces the performance handling capabilities of the backing storage. Tradeoffs!
Additional Considerations
-
Instead of SIOC, consider using per-VM IOPS limits, configurable from VM Storage Policies. These allow for AWS-style IOPS restrictions, with potentially more deterministic storage performance.
-
vSphere 6.5 introduced SIOC v2, configured with VM Storage Policies instead of Disk Shares, but you can still configure SIOC v1. If you refer to 3rd party documentation on the web, make sure you’re looking at an appropriate version.
-
SIOC won’t work on datastores that have more than one extent. If you’ve built your datastore out of multiple LUNs, you can’t use SIOC.
Resources
Storage Distributed Resource Scheduling
Storage DRS (SDRS) is a vCenter feature that offers a long-term solution to balancing storage performance and capacity. To manage performance, SDRS samples I/O latency over a number of hours. If sustained latency is far out of balance, it periodically makes recommendations about virtual machines that could be moved to balance the load. Likewise, if datastores have an imbalance of space allocation, SDRS will recommend VMs to move. If the SDRS cluster is fully automated, it takes initiative, migrating VMs on its own. SDRS takes actions on roughly the granularity of a day.
The latency metric used by Storage DRS is measured at the same level in the I/O stack where virtual machine I/O is injected. Referring back to the diagram in the Storage I/O Control section, it includes latency incurred on the host-side World queue. This is a better measure of “whole system” performance, including inefficiencies on the host.
Additional Considerations
-
Thin provisioning on the Blockbridge side can confuse vCenter’s sense of how much space is available. Configure your Blockbridge datastore with a 1:1 reservable-to-size ratio and use Blockbridge reservation thresholds in addition to VMware datastore disk usage alarms.
-
If you’re using Blockbridge snapshots and backups, you’ll need to coordinate them with the VM migrations. Use manual mode SDRS in this case.
Resources
Storage Performance Classes
Blockbridge dataplanes offer programmatically-defined performance characteristics that give you full control over IOPS and bandwidth quality of service. Whether your deployment consists of a single Blockbridge complex with homogenous storage media or multiple Dataplane complexes with tiered media types, you can configure VMware to deliver multiple classes of storage.
We recommend that you implement storage classes only if your environment consists of mixed application use-cases. For example: if you would like to prevent background processing jobs from affecting the performance of database applications, you may opt for multiple storage classes with segregated performance guarantees (even if they share the same pool of capacity). You should create a separate VMware VMFS datastore for each performance class.
If you use Storage Distributed Resource Scheduling (SDRS), create independent SDRS clusters for each performance class. It is essential to point out that SDRS is not a tiering solution. You should ensure that all VMFS datastores within an SDRS cluster have uniform performance characteristics.
Resources
- VM Storage Profiles and Storage DRS – Part 2 (Frank Denneman) (Older but still valid information on this approach.)
NETWORKING & STORAGE
VMware Multipath Networking
Multipathing is a VMware datastore compliance requirement for network-attached storage. We’ve found that it’s best to get it out of the way before you attempt to connect to storage. Saving it for later frequently results in phantom storage paths that need a reboot to clear out.
The definitive reference for ESXi iSCSI multipath configuration is, unfortunately, several years old: Multipathing Configuration for Software iSCSI Using Port Binding (VMware). Still, the document is very thorough and mostly accurate today. If you have a complicated install, you should give it a read.
Requirements for Common Network Architectures
There are several common network patterns used for highly available iSCSI storage.
Mode A: Single Subnet Nx1
- ESXi has N interface ports, each with an IP address on the same subnet.
- Blockbridge has a single logical or physical interface port configured with a single IP address.
Mode B: Single Subnet NxM
- ESXi has N interface ports, each with an IP address on the same subnet.
- Blockbridge has M logical or physical interface ports, each with an IP address on the same subnet.
Mode C: Multiple Subnet NxN
- ESXi has N interface ports, each with an IP address on a different subnet.
- Blockbridge has N logical or physical interface ports, each with an IP address on different subnets.
If your ESXi interface ports are on different subnets, no additional network configuration is required for multipathing. If your ESXi interface ports share a subnet, you must configure iSCSI Port Bindings.
Virtual Networking - VMkernel Adapters & vSwitches
This section offers a simplified description of the process for configuring VMkernel Network Adapters and Virtual Switching in support of iSCSI multipathing deployed on a single subnet. Specific attention is paid to changes found in the vCenter 6.7 HTML interface. Configuration via the CLI is also possible: see Multipathing Configuration for Software iSCSI Using Port Binding (VMware) for details.
To start, Launch the Add Networking wizard for your host:
-
Select the host from the sidebar menu.
-
Select Configure.
-
Expand Networking.
-
Select VMkernel Adapters.
-
Select Add Networking.
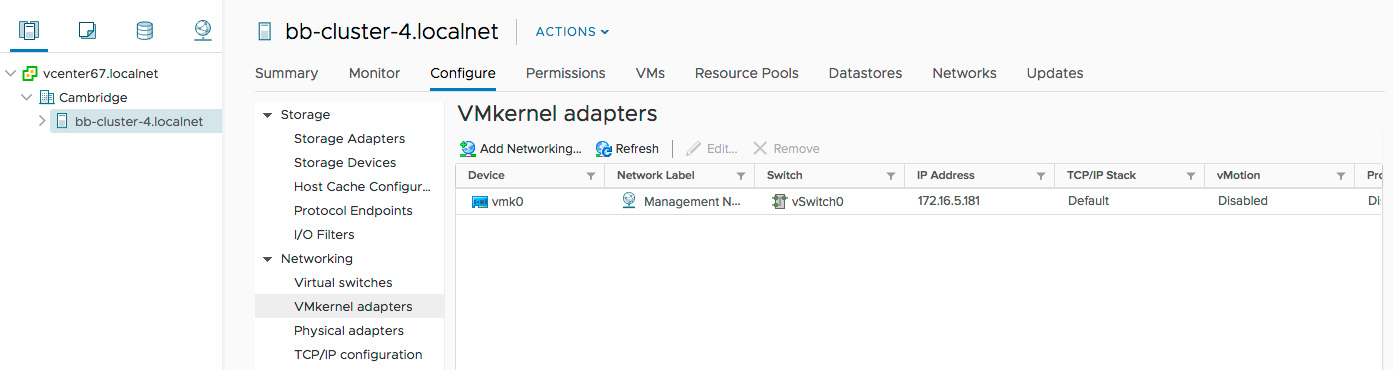
Create a new VMkernel Adapter and vSwitch:
-
Select VMkernel Network Adapter as the connection type.
- Select New standard switch to create a vSwitch.
- Set an MTU value compatible with your network.
-
Assign participating physical interfaces to the vSwitch by clicking the green “+” button. Here, we’ve added vmnic2 and vmnic1000202.
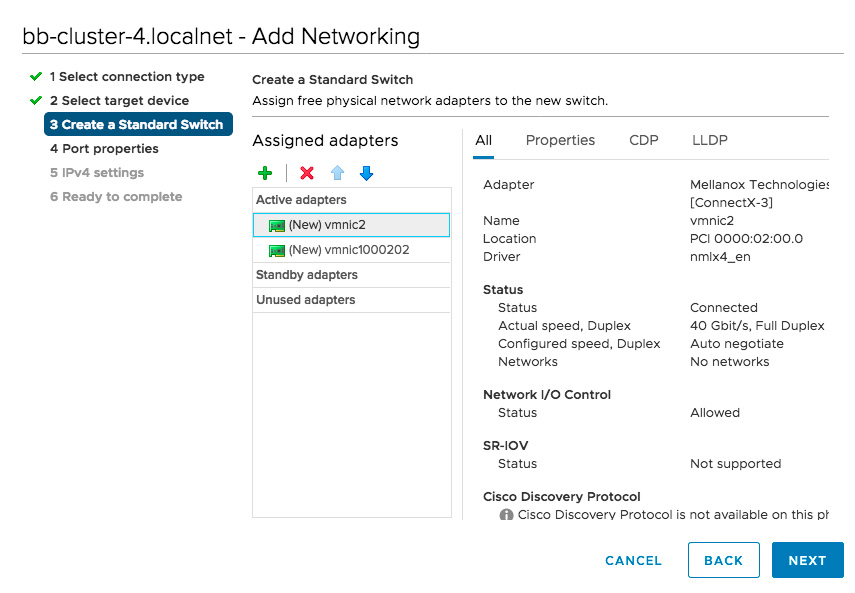
- Edit the VMkernel Adapter Port properties.
- Enable vMotion and Provisioning data services.
- Specify a Network Label that makes it clear that this is one of several ports used for iSCSI traffic. In our example, we chose “iSCSI pg1”.
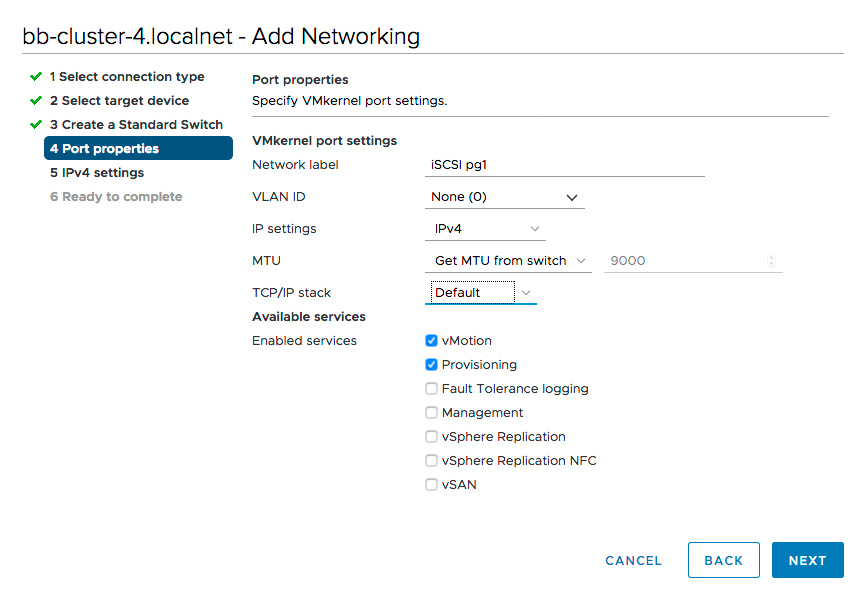
- Edit the IPv4 settings
- enter the IP address and netmask for the VMkernel Adapter Port.
- Finally, complete the workflow.
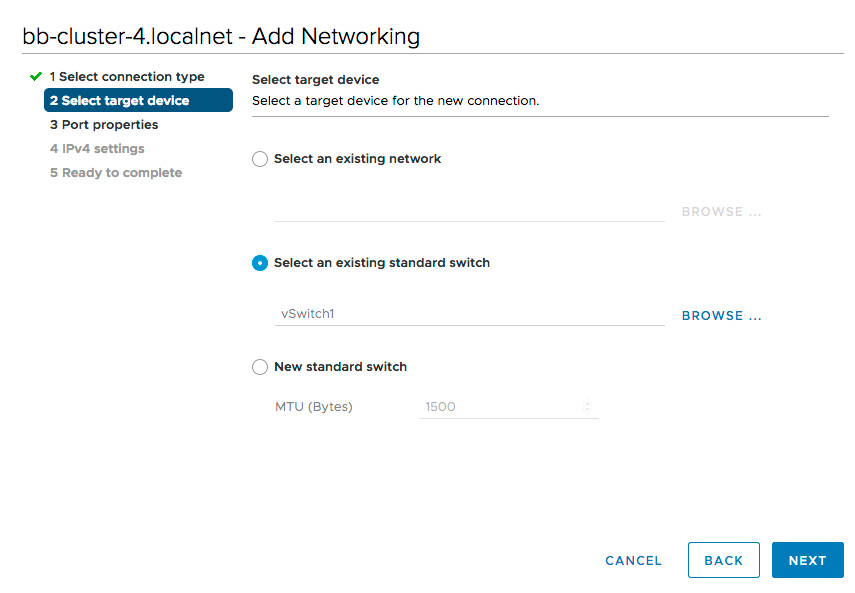
Create VMkernel Adapters for each additional physical network interface port, adding them to your existing vSwitch. This is the same process as above, substituting step 2 as follows:
-
For the target device, Select an existing standard switch. Specify the vSwitch created previously.
On completion, you should see the two VMkernel adapters:
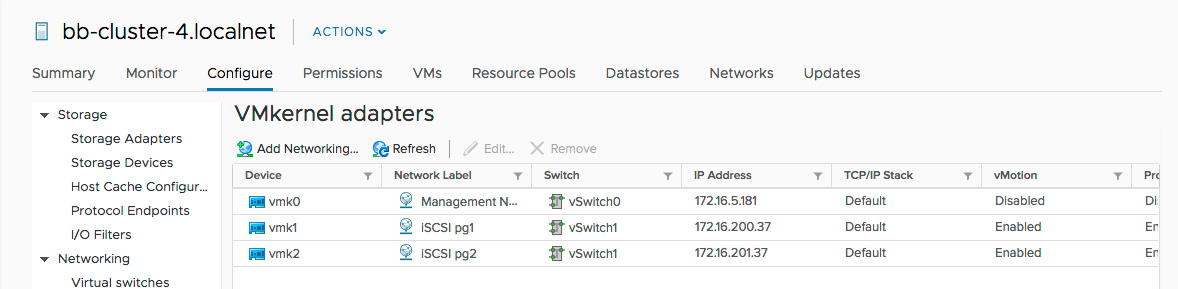
Virtual Networking - Physical Adapter Selection
At this point, you have created a vSwitch that connects multiple VMkernel Adapters with multiple Physical Adapters. By default, VMware will use a single physical adapter for outbound traffic from the vSwitch. To use additional physical adapters, you must apply a policy to each VMkernel Adapter that binds outbound traffic to single Physical Adapter.
To start, locate your vSwitch Network Diagram
- Select Networking / Virtual switches.
- Scroll down as needed to find your vSwitch.
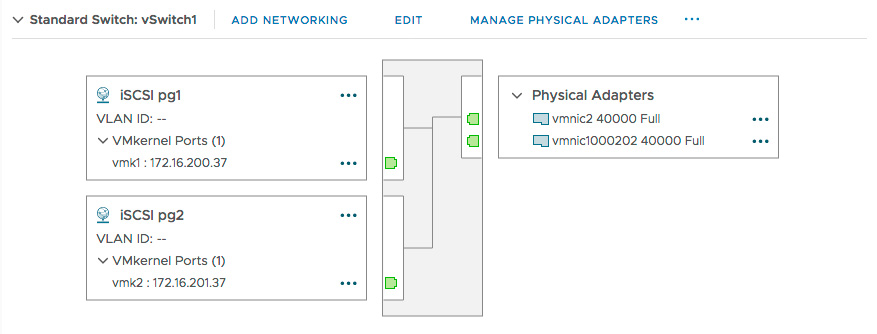
Next, edit the configuration of each VMkernel adapter.
-
Select the three dots to the right of the first VMkernel adapter (here, it’s “iSCSI pg1”).
-
Select Edit Settings.
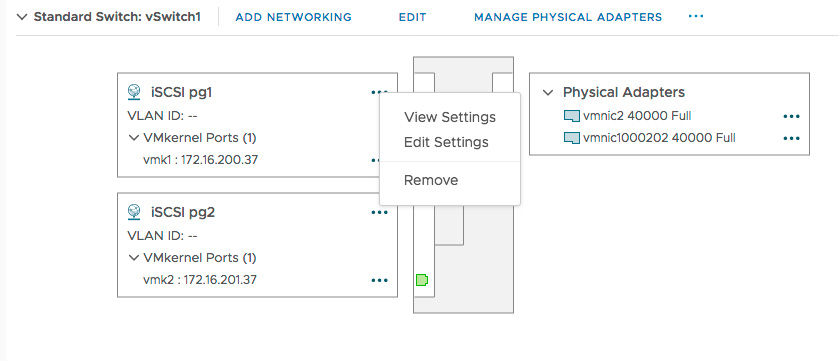
-
Select Teaming and failover in the edit settings dialog.
-
Select the checkbox next to Override
-
Assign a Single Physical Adapter as an Active Adapter
- Assign all other adapters as Unused Adapters.
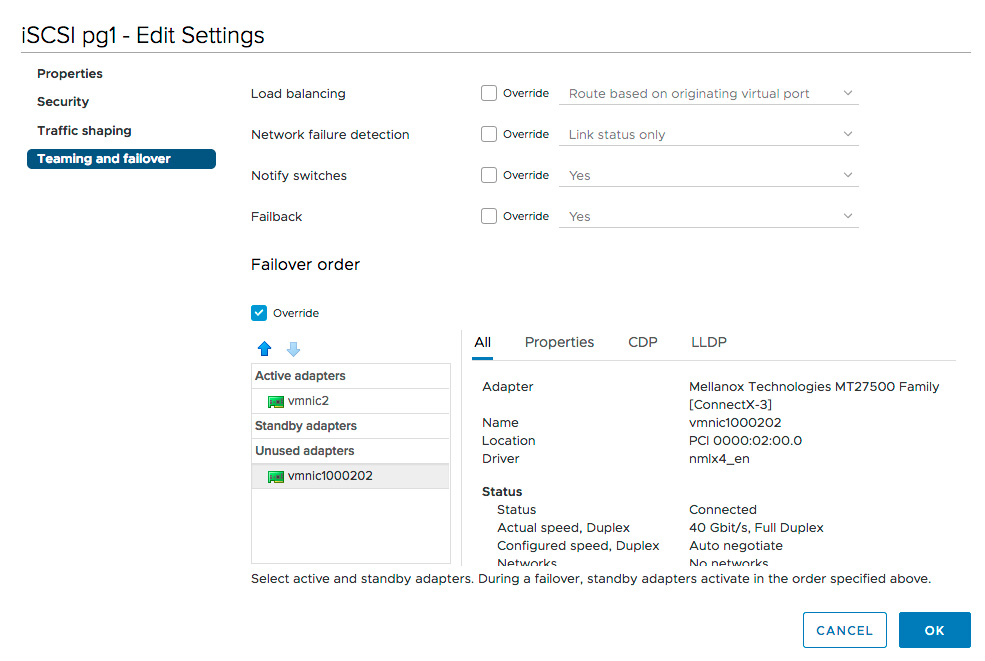
Repeat this process for each VMkernel adapter, ensuring each adapter maps to a unique Physical Adapter. In the example below, our “iSCSI pg2” adapter assigns “vmnic1000202” as active since “iSCSI pg1” previously assigned “vmnic2”.
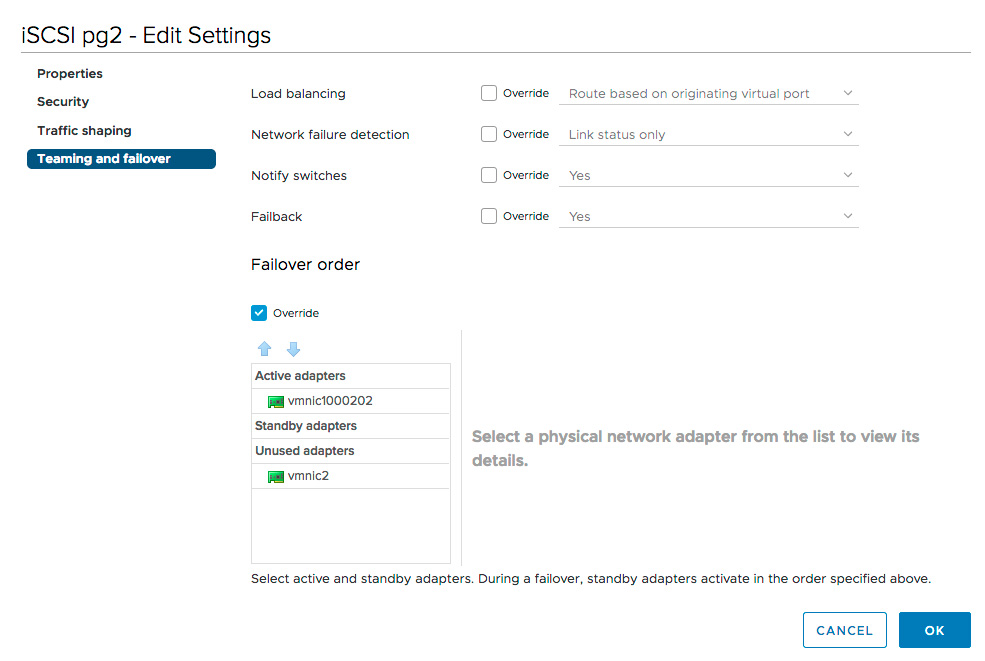
Network Port Bindings for iSCSI
At this point, you have multiple VMkernel adapters that are mapped to independent Physical Adapters configured with IP addresses on the same subnet. The last step is to configure network port bindings in the VMware Software iSCSI Adapter.
-
Select Storage / Storage Adapters.
-
Select the iSCSI Software Adapter.
-
Select Network Port Binding.
-
Select Add.
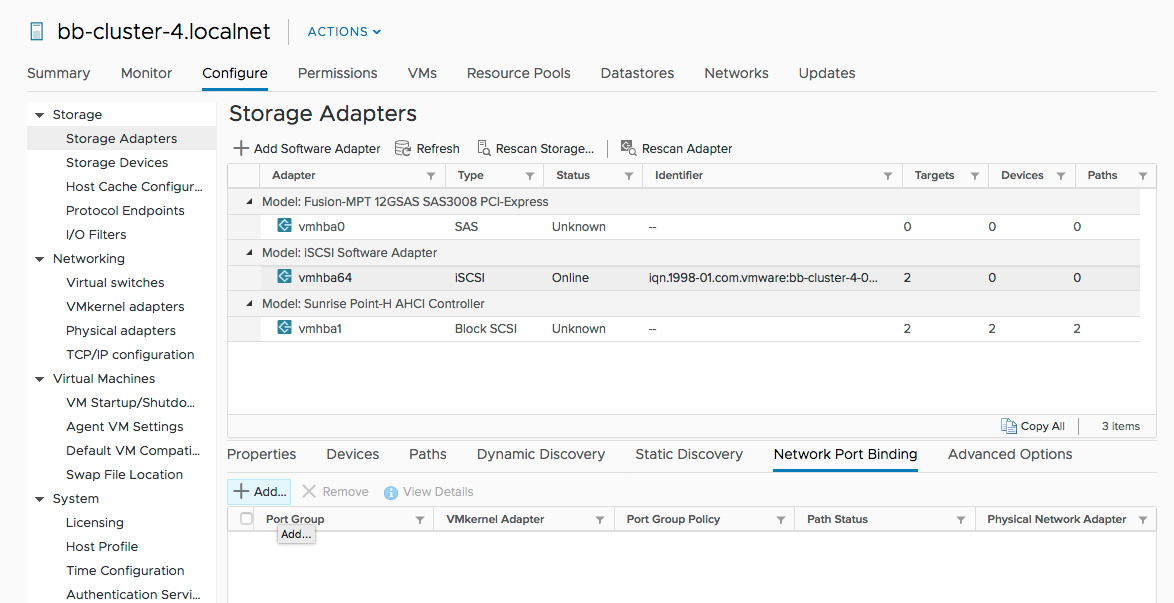
-
Select your VMkernel Adapters, then select OK.
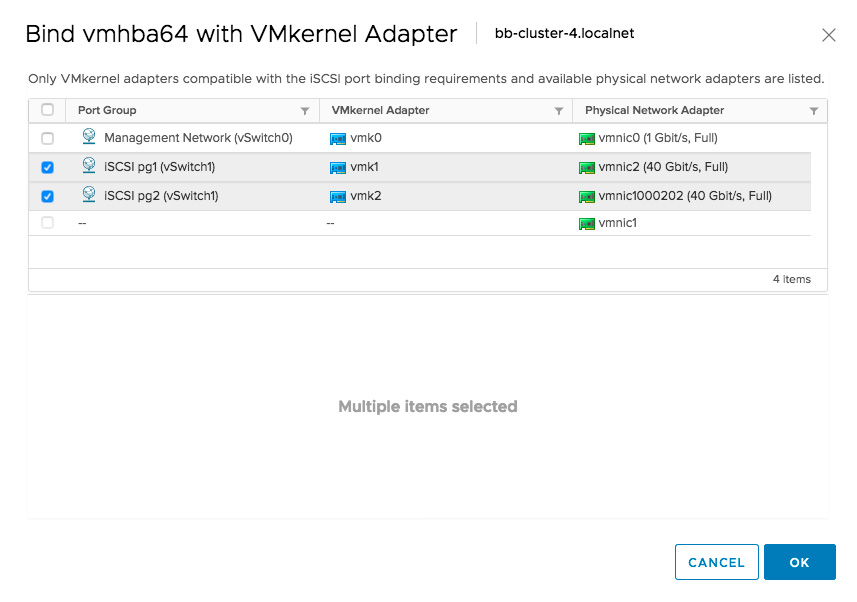
Resources
-
Multipathing Configuration for Software iSCSI Using Port Binding (VMware)
-
When To Use Multiple Subnet iSCSI Network Design (Chris Wahl)
-
VMware vSphere - When to use iSCSI Port Binding, and why! (Stephen Wagner)
-
ESXi iSCSI, Multiple Subnets, and Port Binding (Cody Hosterman)
-
Considerations for using software iSCSI port binding in ESX/ESXi (2038869) (VMware KB)
LACP & Bonded Networking
If your network configuration consists of bonded network interfaces that use the Link Aggregation Control Protocol (LACP), we recommend that you configure “fast rate” (also known as “lacp short-timeout”). “Fast rate” improves link failure recovery times from the default value of 30 seconds to 1 second. Proper setup requires consistent configuration settings on your host interfaces and corresponding switch ports.
We also recommend that you configure passive transmit hashing on bonded interfaces. Transmit hashing ensures that the ethernet packets of a single network flow transmit on the same network link. Transmit hashing reduces the probability of packet reordering and performance loss for iSCSI/TCP. We recommend that you incorporate both L3 (i.e., source and destination IPv4 and IPv6 addresses) and L4 (i.e., source and destination ports) in your hash configuration for efficient flow distribution across your network links.
The example below shows a Linux team configuration with active/active LACP and l3/l4 transmit hashing.
# teamdctl t0 config dump
{
"device": "t0",
"link_watch": {
"name": "ethtool"
},
"ports": {
"fe0": {},
"fe1": {}
},
"runner": {
"active": true,
"fast_rate": true,
"name": "lacp",
"tx_hash": [
"l3",
"l4"
]
}
}
Provisioning iSCSI Storage
This section describes how to provision and configure your Blockbridge storage for use with a VMware datastore. You’ll create one or more virtual storage services distributed across your dataplane complexes. Inside those storage services, you will create a virtual disk and an iSCSI target for each VMware datastore that you want to create. A global set of CHAP credentials will serve to authenticate your VMware cluster to the Blockbridge dataplane endpoints.
Start by logging in to the administrative “system” user in the Blockbridge web GUI. On the infrastructure tab, manually provision a virtual storage service (VSS) on each dataplane complex that will connect to your VMware installation. If you plan to create multiple VMware datastores per dataplane complex, create the disks to back them inside a single virtual service.
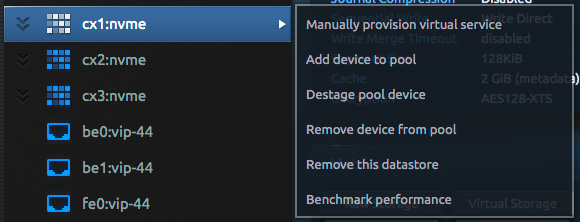
Select “Manually provision virtual service”. On the dialog window that pops up, create a label for the service that references the label of the dataplane complex. You may create the service inside the “system” account, or you may wish to create a dedicated account for your VMware storage.
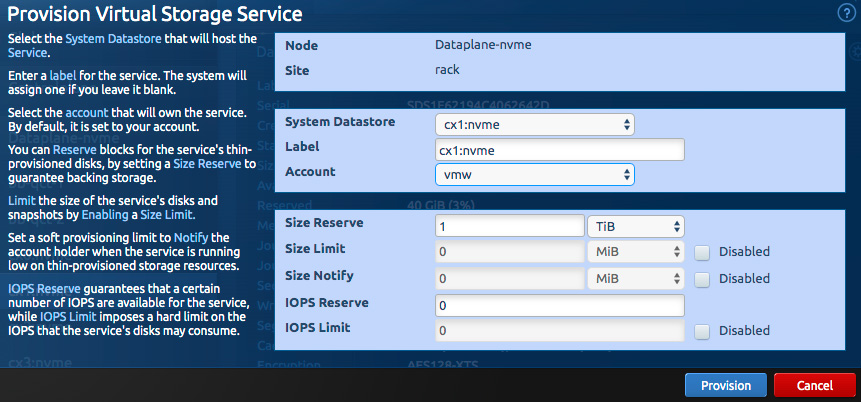
Reserve enough size to hold the contents of the VMware datastores you intend to create. If you created the VSS in a different account (as we did with the “vmw” account here), log out, and log back in as that account.
The easiest way of managing authentication for your VMware deployment is to use a global initiator profile. Create one from the flyout menu off of Global, in the Storage tab.

In the “Create Initiator Profile” dialog that opens, enter a CHAP username (here, “esx@vmw”) and a CHAP secret, with confirmation.
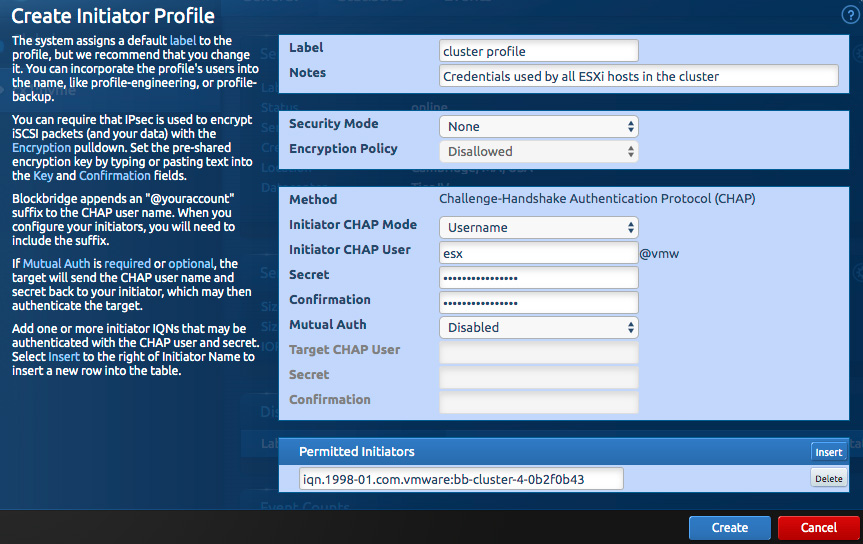
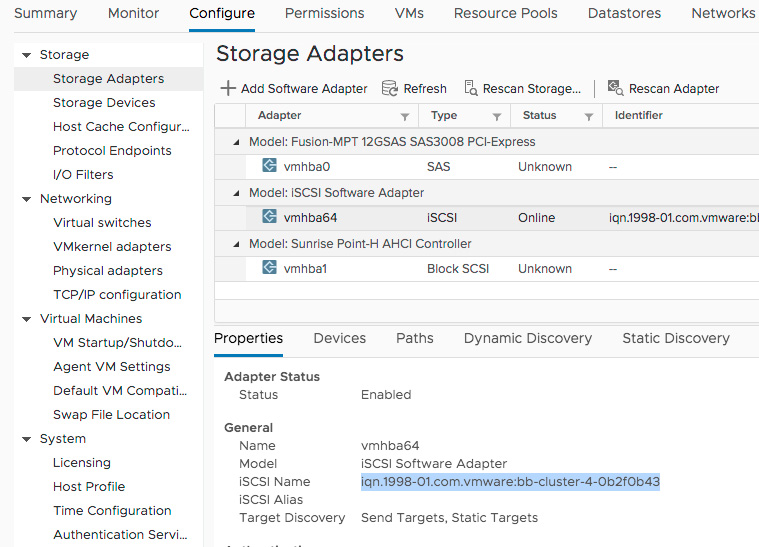
You will need the iSCSI IQN from the iSCSI adapter in each ESXi host.
Paste each host’s IQN into the “Permitted Initiators” section of the dialog then click “create”.
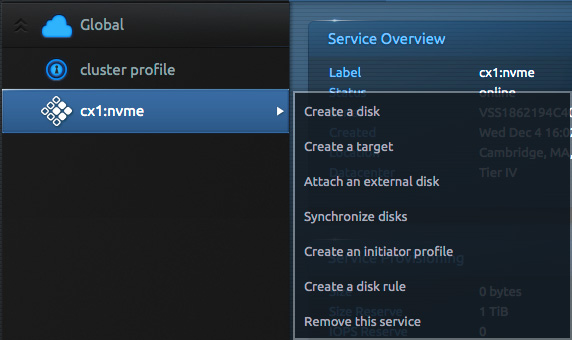
Next, create one or more disks in the service to host your VMFS datastores. If you have several disks to create, you may wish to move to the Blockbridge CLI tool to do it. Both the GUI and CLI are covered below.
Select “Create a disk” from the storage service’s flyout menu, shown below.
Enter the size of the disk in the dialog that pops up, along with an appropriate label. Click “create”.
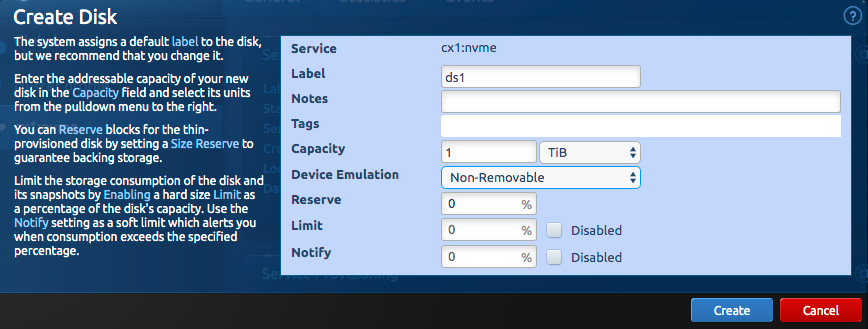
From the CLI, it’s:
bb disk create --vss cx1:nvme --label ds1 --capacity 1TiB
Next, create an iSCSI target on the Blockbridge side for each disk you created above. Creating one target per disk ensures that each LUN has an independent iSCSI command queue. Select “Create a target” from the virtual storage service’s flyout menu (shown earlier).
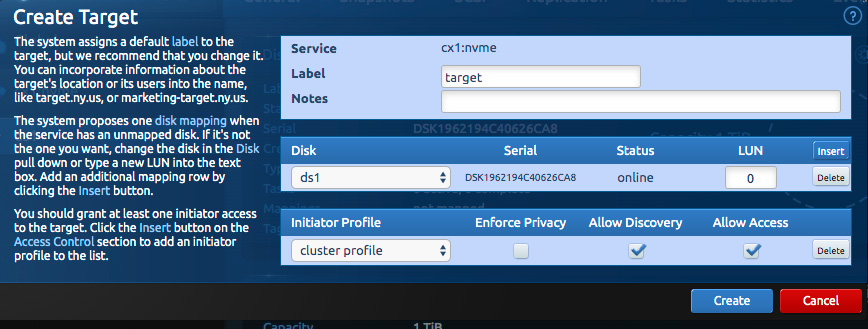
On each target, select “insert” to add one disk. Select the label of the global initiator profile you created earlier to grant access via those credentials.
Creating a target is a multi-step process from the CLI:
bb target create --vss cx1:nvme --label target
bb target acl add --target target --profile "cluster profile"
bb target lun map --target target --disk ds1
Repeat this procedure for each disk.
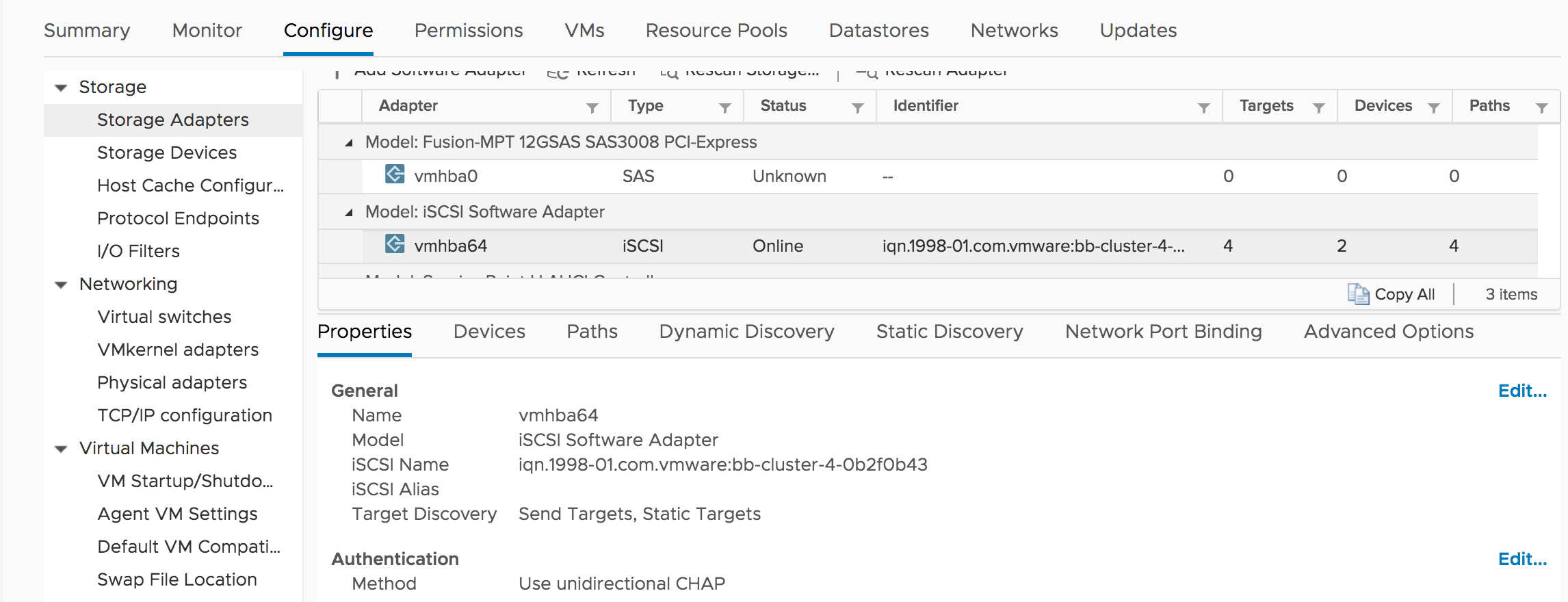
VMware Initiator Configuration
From the vSphere GUI, select the iSCSI adapter. Under Properties, scroll down to Authentication. Select Edit…
Enter the CHAP username and secret from the Blockbridge initiator profile. Blockbridge targets support mutual authentication – a good idea if you’re concerned about an attacker interposing an illegitimate iSCSI target in your infrastructure.
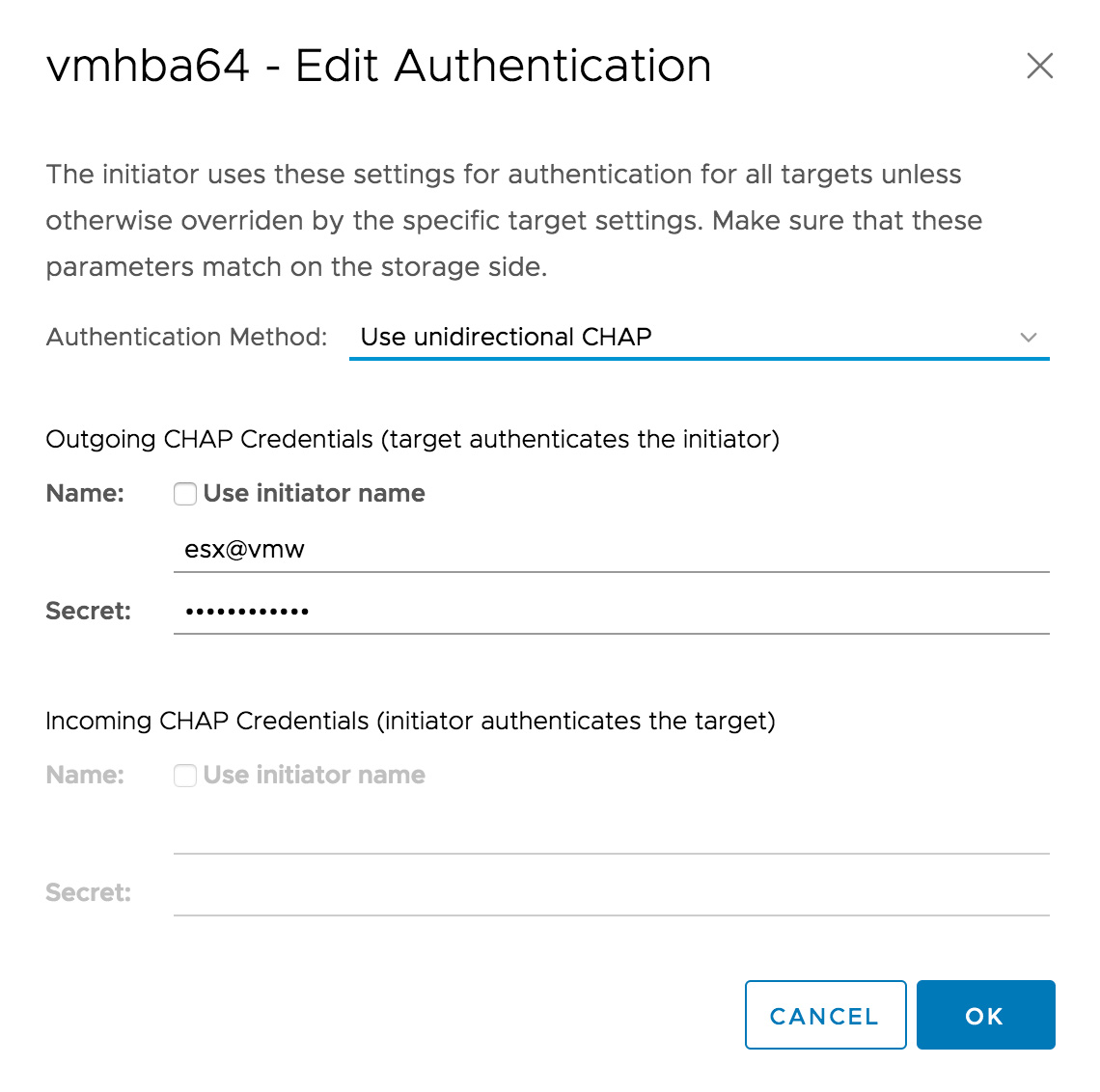
Note that VMware’s iSCSI software adapter is limited to one set of “parent” CHAP authentication credentials that can be inherited into the static and dynamic targets. If you need to use other iSCSI targets with different credentials, you can unclick “Inherit authentication settings from parent” and enter a new set of CHAP credentials each time you add a target.
Dynamic Discovery
Staying on the iSCSI software adapter, select Dynamic Discovery, then click Add…
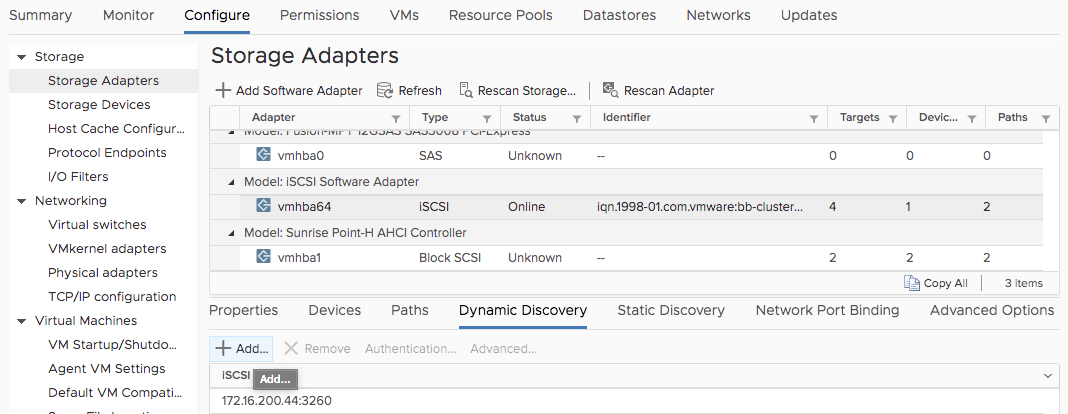
On the dialog that pops up, enter one of the Blockbridge target’s portal IP addresses, along with the port.
Alternatively, add the dynamic discovery target with esxcli:
esxcli iscsi adapter discovery sendtarget add --adapter=vmhba64 --address=172.16.200.44:3260
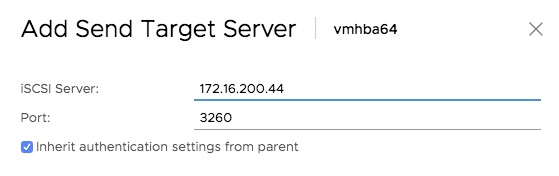
Static Discovery
In the rare instance that you need to use static target discovery, here’s how to do it. Select Static Discovery, then click Add…
On the dialog that pops up, enter one of the Blockbridge target’s portal IP addresses, along with the port, and the target’s IQN. Note that the port in this case is 3261.

With static discovery, you have to add each path manually. You may find it easier to use esxcli to add static targets. The following example adds paths for two target portal IP addresses.
esxcli iscsi adapter discovery statictarget add --adapter=vmhba64 --address=172.16.200.44:3261 \
--name=iqn.2009-12.com.blockbridge:t-pjwahzvbab-nkaejpda:target
esxcli iscsi adapter discovery statictarget add --adapter=vmhba64 --address=172.16.201.44:3261 \
--name=iqn.2009-12.com.blockbridge:t-pjwahzvbab-nkaejpda:target
Per-Target CHAP
If you need per-target CHAP settings, update the target with the following command. It will prompt you to enter the secret, so it doesn’t show up in command line logs.
esxcli iscsi adapter target portal auth chap set --adapter=vmhba64 \
--direction=uni --authname=esx@vmw \
--secret --level=required --address=172.16.200.44:3261 \
--name=iqn.2009-12.com.blockbridge:t-pjwahzvbab-nkaejpda:target
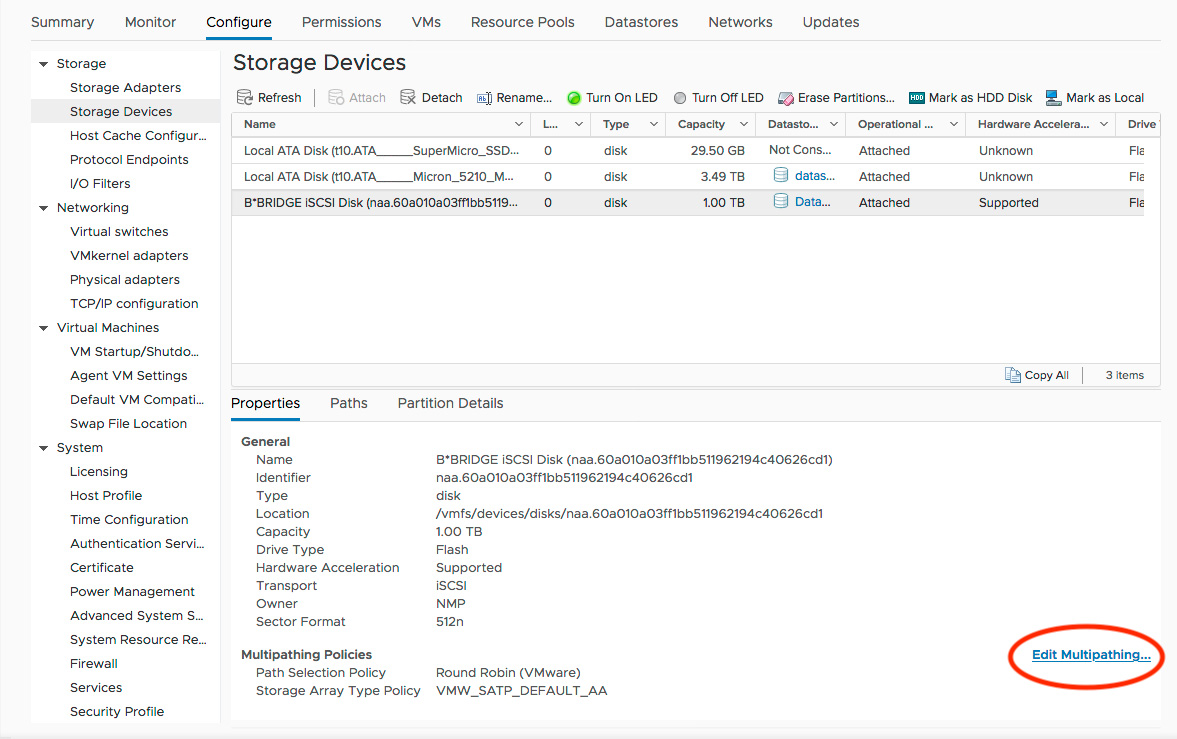
Path Selection Policy
Next up, change the multipathing policies for each LUN to Round Robin. From the vSphere GUI, click Edit Multipathing… then change the policy.
Alternatively, from esxcli, list the devices with:
esxcli storage nmp device list
And set the roundrobin policy on a device with:
esxcli storage nmp device set --psp=VMW_PSP_RR --device=naa.60a010a071105fae1962194c40626ca8
Note that the --psp and --device options must be specified in the order
shown. The command inexplicably fails if you swap them.
To change the path selection policy of all “naa.” devices in bulk, wrap the command in a for loop, as follows:
for dev in $(esxcli storage nmp device list | egrep ^naa); do
esxcli storage nmp device set --psp=VMW_PSP_RR --device=${dev}
done
Finally, verify that all paths to each device are working. Select Storage Devices -> Paths. Each path should show Active status. Neither path should have any indicator in the “Preferred” column.
Creating a VMFS Datastore
Create one VMFS datastore for each disk created above.
Whenever possible, use VMFS version 6. VMFS-6, introduced with vSphere 6.5, includes numerous performance and stability improvements. In particular, the following enhancements are notable for Blockbridge installations:
-
VMFS-6 metadata is aligned to a 4 KiB blocksize.
-
It has improved miscompare handling for ATS heartbeats,
-
reduced lock contention, and
-
supports multiple concurrent transactions.
We recommend VMFS-6 for all new installations.
To create the datastore, right-click on a host then select Storage -> New Datastore. We recommend creating the datastore from a single disk and setting its size to consume 100% of that disk.
Resources
HOST TUNING
iSCSI LUN Queue Depth
The iSCSI LunQDepth parameter controls the number of concurrent I/O operations that ESXi can issue on a single iSCSI session before queuing occurs in the host.
If your goal is maximum performance from a small population of hosts (i.e., <= 4), we recommend that you increase LunQDepth to 192. If you have a large number of ESXi hosts that are sharing a single datastore, the default value of LunQDepth (i.e., 128) is appropriate. In this situation, we recommend that you enable Disk.QFullSampleSize.
Increasing the queue depth requires a host reboot. Use the following esxcli command to increase the queue depth. Then, reboot the ESXi host.
esxcli system module parameters set -m iscsi_vmk -p iscsivmk_LunQDepth=192
After reboot, validate that your iSCSI devices have the increased “Device Max Queue Depth”.
esxcli storage core device list
...
naa.60a010a03ff1bb511962194c40626cd1
Display Name: B\*BRIDGE iSCSI Disk (naa.60a010a03ff1bb511962194c40626cd1)
Has Settable Display Name: true
Size: 1048576
...
Device Max Queue Depth: 192
No of outstanding IOs with competing worlds: 32
In a Linux guest, spin up this 192 queue depth, 4K random read workload with fio. This example uses reads on the root disk. Do not change this test to write.
[global]
rw=randreadT
bs=4096
iodepth=192
direct=1
ioengine=libaio
time_based
runtime=180
numjobs=1
[local]
filename=/dev/sda
From the ESXi console, run esxtop and press “u” to get the storage view. Validate that more than 128 commands are outstanding in the ACTV column:
9:42:43pm up 13 min, 551 worlds, 2 VMs, 6 vCPUs; CPU load average: 1.46, 1.49, 0.00
DEVICE PATH/WORLD/PARTITION DQLEN WQLEN ACTV QUED %USD LOAD CMDS/s READS/s WRITES/s
naa.60a010a03ff1bb511962194c40626cd1 - 192 - 210 0 82 0.82 232971.42 232971.23 0.00
SchedNumReqOutstanding Depth
esxcli storage core device set --sched-num-req-outstanding
vSphere has a special setting that controls how deep the I/O queue is for a guest when other guests are accessing the same storage device. In earlier versions of ESXi, this used to be controlled via the global parameter Disk.SchedNumReqOutstanding. But starting in 5.5, control has been relegated to an esxcli-only parameter, viewable in the output of esxcli storage core device list: “No of outstanding IOs with competing worlds”, like this;
[root@esx:~] esxcli storage core device list
naa.60a010a0b139fa8b1962194c406263ad
Display Name: B*BRIDGE iSCSI Disk (naa.60a010a0b139fa8b1962194c406263ad)
...
Device Max Queue Depth: 128
No of outstanding IOs with competing worlds: 32
If only one guest is sending I/O to a storage device, it’s permitted to use the full queue depth. As soon as a second guest begins accessing the device, by default, the queue depth of each guest drops to 32.
Generally, we recommend increasing this setting to 64 if you’ve increased the iSCSI LUN queue depth to 192. In situations where multiple guests are accessing a device at the same time, the queue depth of 64 ensures that no guest claims more than their fair share of the storage performance, yet still has enough depth to get commands out to the LUN. And, as will be the case much of the time, when only one guest is accessing the device, it can do so with the full depth of the device’s queue.
In some situations, even this behavior is not desirable. You can confirm this is happening to your guests by running esxtop and watching the DQLEN column. If it’s stuck at 32 (or 64) for multiple guests, it’s a safe bet they’re subject to this parameter. If you believe that your guest workloads are unfairly penalized by this setting, try increasing it to the device queue depth (192).
[root@esx:~] esxcli storage core device set --sched-num-req-outstanding 192 -d naa.60a010a0b139fa8b1962194c406263ad
Queue Depth Throttling
vSphere can dynamically reduce its queue size if the backing storage reports a SCSI TASK SET FULL or BUSY status. When the number of observed conditions reaches QFullSampleSize, the device queue depth reduces by half. After QFullThreshold successful command completions, the queue depth increases by one, to a maximum of LunQDepth.
For a small population of ESXi hosts:
- Confirm that Queue Full Sample Size is 0.
For a large population of ESXi hosts:
- Enable Adaptive Queue Throttling.
esxcli storage core device set --device device_name --queue-full-sample-size 32 --queue-full-threshold 128
Round Robin Path Selection IOPS Limit
esxcli storage nmp psp roundrobin deviceconfig set ...
By default, the round-robin iSCSI multipathing plug-in sends 1,000 I/O’s down one active path before switching to another. This technique often fails to unlock the full bandwidth of multiple paths. With a queue depth of 128 or 192, the workload “sloshes” back and forth between the two paths, rather than saturating both of them. By lowering the I/O limit to 8, VMware switches paths after every eight I/O’s issued, more efficiently using the network.
Quite a few vendors recommend lowering this limit to 1 I/O. However, there are some processing efficiencies to be had by staying on the same path for several I/O’s in a row. Notably, using a slightly larger setting (like 8) interacts favorably with NIC receive coalescing on the Blockbridge side for writes, and on the ESXi side for reads.
The change can only be made from the command line. Use esxcli storage nmp device list to display the SCSI ID’s of your devices and their current path selection policies:
esxcli storage nmp device list
naa.60a010a03ff1bb511962194c40626cd1
Device Display Name: B*BRIDGE iSCSI Disk (naa.60a010a03ff1bb511962194c40626cd1)
Storage Array Type: VMW_SATP_DEFAULT_AA
Storage Array Type Device Config: {action_OnRetryErrors=off}
Path Selection Policy: VMW_PSP_RR
Path Selection Policy Device Config: {policy=rr,iops=1000,bytes=10485760,useANO=0; lastPathIndex=0: NumIOsPending=0,numBytesPending=0}
Path Selection Policy Device Custom Config:
Working Paths: vmhba64:C1:T0:L0, vmhba64:C0:T0:L0
Is USB: false
Set the type to “iops” and the limit to 8:
esxcli storage nmp psp roundrobin deviceconfig set --type=iops --iops=8 \
--device=naa.60a010a03ff1bb511962194c40626cd1
View the results:
esxcli storage nmp device list
naa.60a010a03ff1bb511962194c40626cd1
Device Display Name: B*BRIDGE iSCSI Disk (naa.60a010a03ff1bb511962194c40626cd1)
Storage Array Type: VMW_SATP_DEFAULT_AA
Storage Array Type Device Config: {action_OnRetryErrors=off}
Path Selection Policy: VMW_PSP_RR
Path Selection Policy Device Config: {policy=iops,iops=8,bytes=10485760,useANO=0; lastPathIndex=1: NumIOsPending=0,numBytesPending=0}
Path Selection Policy Device Custom Config:
Working Paths: vmhba64:C1:T0:L0, vmhba64:C0:T0:L0
Is USB: false
Alternatively, view the path selection policy directly,
esxcli storage nmp psp roundrobin deviceconfig get -d naa.60a010a03ff1bb511962194c40626cd1
Byte Limit: 10485760
Device: naa.60a010a03ff1bb511962194c40626cd1
IOOperation Limit: 8
Latency Evaluation Interval: 0 milliseconds
Limit Type: Iops
Number Of Sampling IOs Per Path: 0
Use Active Unoptimized Paths: false
Resources
VAAI Commands
The Blockbridge dataplane fully supports the VAAI command set, including:
-
offloaded storage vMotion with EXTENDED COPY,
-
server-side locking with COMPARE AND WRITE, and
-
server-side zeroing with WRITE SAME 10 and 16.
All of these parameters should be enabled with a value of “1”, under Advanced System Settings. By default, they’re enabled, so no change should be required.
ATS Heartbeating (VMFS-6)
Keep this parameter set to the default value of 1 for ESXi 6.5 or newer installations with VMFS-6 volumes. Blockbridge fully supports the SCSI “atomic test and set” COMPARE AND WRITE command. (It’s also used for VAAI Storage vMotion.) It doesn’t cause any notable load on the data plane. The legacy alternative to ATS heartbeating is more cumbersome.
Versions of ESXi earlier than 6.5, or those using VMFS-5 volumes, may not have properly handled ATS timeouts, incorrectly registering “miscompares”. For these older versions of ESXi, it’s best to disable this setting.
Resources
Halt VMs on Out-of-Space Conditions
If a volume backing a datastore runs out of space, VMware thoughtfully pauses any VM that attempts to allocate storage, instead of passing the error through. Many applications do not handle out-of-space particularly well, so this option can be a lifesaver. Documents from VMware refer to this as the “thin provisioning stun” feature. It’s enabled by default, with Disk.ReturnCCForNoSpace = 0. Setting ReturnCCForNoSpace to “0” instructs VMware to not return an error (a SCSI CHECK CONDITION) when it runs out of space. We recommend that you leave this set to 0, allowing it to pause the VMs.

The SCSI status 0x7/0x27/0x7 is SPACE ALLOCATION FAILED – WRITE PROTECT.
Jumbo Frames
You may be able to squeeze out the last 5% of performance by switching to jumbos. But they can come with significant costs, both in implementation and in the debug time associated with strange problems. If you’re already using jumbo frames at L2, you’ll need to make sure you’ve configured vSphere for jumbo frames. If you’re not using jumbos yet, consider carefully whether you want to undertake the transition.
-
Navigate to Host -> Configure -> Networking / VMkernel adapters
-
For each adapter the must be modified:
a. Click the pencil icon,
b. Select “NIC settings”,
c. Change the MTU to 9000, and
d. Press “OK”.
-
Navigate to “Virtual switches”
-
For each vSwitch to be modified:
a. Click the pencil icon,
b. Under “Properties”, change the MTU to 9000, and
c. Press “OK”.
Use vmkping to test that jumbo frames are configured.
vmkping -ds 8972 <IP of Blockbridge storage service>
Resources
iSCSI Login Timeout
Plan for a Blockbridge dataplane failover time of 30 seconds. This is transparent for applications and virtual machines, so long as the timeouts are set to be long enough. During a dataplane failover, ESXi’s iSCSI adapter notices that the session is unresponsive, typically within 10 seconds. It attempts to reconnect and login. The LoginTimeout setting must be long enough to successfully ride out a failover. We recommend 60 seconds, to be on the safe side.
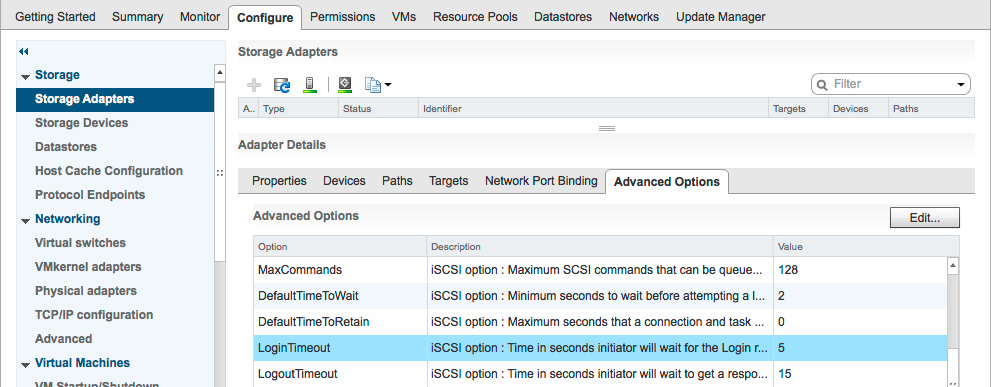
From the CLI:
esxcli iscsi adapter param set --adapter=vmhba64 --key=LoginTimeout --value=60
TCP DelayedAck
DelayedAck was intended to boost performance by reducing the number of TCP segment acknowledgements. Several years back, this triggered some strange performance problems with certain iSCSI arrays with very custom TCP/IP stacks. These arrays were effectively acknowledging every other TCP segment, and could be left waiting periodically for VMware’s delayed ACK.
Blockbridge isn’t subject to any problems related to the use (or non-use) of DelayedAck. Our stance is that it’s very unlikely to make a difference either way.
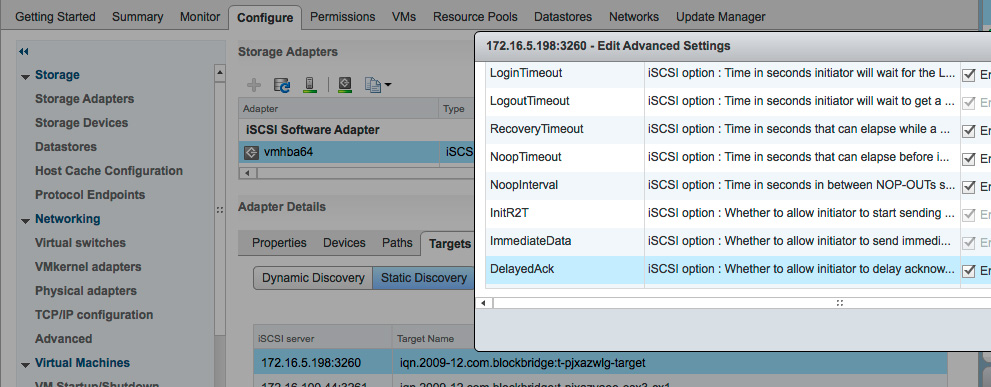
If you choose, you can disable DelayedAck for the iSCSI adapter or for individual targets. The per-adapter setting is on the Advanced Options tab for the iSCSI software adapter. Drill down a couple more layers to access the per-target setting, by clicking on the Targets tab in the adapter, then Dynamic Discovery or Static Discovery, select the appropriate target, and click Advanced. Un-check Inherit for the setting, then disable it.
Large Receive Offload Maximum Length
The /Net/VmxnetLROMaxLength parameter sets the size of the Large Receive Offload (LRO) buffer. By default, it’s set to 32,000 bytes. Increasing the size of this may improve throughput.
esxcfg-advcfg -s 65535 /Net/VmxnetLROMaxLength
NIC Interrupt Balancing
Leave NIC interrupt balancing set to the default: enabled.
esxcli system settings kernel set -s intrBalancingEnabled -v true
Yes, to achieve the lowest possible latency, you ideally want explicit control over the CPU core where interrupts are processed, and also where everything else on the system is scheduled. But, it’s very difficult to capture and maintain that kind of control on an ESXi server. We recommend that you accept the default balancing. ESXi appears to do a decent job of avoiding cores under heavy utilization by VMs.
As this is a kernel setting, it requires a reboot to take effect.
Mellanox Specific Optimizations
On ConnectX-3 NICs, we recommend disabling adaptive receive interrupt moderation. On newer cards, it behaves well. But it doesn’t seem to quite do the right thing on these older NICs. In addition to this change, increase the size of the NIC’s ring buffer, explicitly eliminate transmit coalescing, and set a modest value of 3 microseconds for receive coalescing. Be sure to do it for all ports.
esxcli network nic ring current set -r 4096 -n vmnicX
esxcli network nic coalesce set --tx-usecs=0 --rx-usecs=3 --adaptive-rx=false -n vmnicX
Verify the tunings:
# esxcli network nic coalesce get
NIC RX microseconds RX maximum frames TX microseconds TX Maximum frames Adaptive RX Adaptive TX Sample interval seconds
------------ --------------- ----------------- --------------- ----------------- ----------- ----------- -----------------------
vmnic0 N/A N/A N/A N/A N/A N/A N/A
vmnic1 N/A N/A N/A N/A N/A N/A N/A
vmnic1000202 3 15 0 1 Off Off 0
vmnic2 3 15 0 1 Off Off 0
This optimization reduced the latency observed in the guest of a queue depth 1 4K read workload from 90us to 70us!
On ConnectX-4 or newer NICs, increase the size of the ring buffer, enable adaptive-rx, and disable transmit coalescing:
esxcli network nic ring current set -r 4096 -n vmnicX
esxcli network nic coalesce set --tx-usecs=0 --adaptive-rx=true -n vmnicX
GUEST TUNING
Paravirtual SCSI Adapter
Whenever possible, select the Paravirtual SCSI adapter for the SCSI controller in each guest VM. This adapter offers the best performance and lowest CPU utilization of any of the available options. It’s also the only virtual adapter with a queue depth larger than 32 per device.
Linux kernels going all the way back to 2.6.33 include the necessary vmw_pvscsi driver. For Microsoft Windows guests, install VMware tools.
Consult VMware’s KB article (below) for details on changing the queue depths of the Paravirtual SCSI adapter inside the guest OS. Unlike the defaults in the article, recent Linux installs seem to be defaulting to 190 queue depth with 32 ring pages, so your installation may not need additional tuning:
[root@esx]# cat /sys/module/vmw_pvscsi/parameters/cmd_per_lun
190
[root@esx]# cat /sys/module/vmw_pvscsi/parameters/ring_pages
32
Resources
Virtual Machine Encryption
We recommend avoiding encrypted VMware virtual disks, for a few reasons:
-
Data stored in Blockbridge is always encrypted at rest.
-
Blockbridge data encryption is done in the storage hardware; your hypervisors won’t spend any CPU cycles on the cryptography.
-
Blockbridge dataplanes will not be able to use data reduction techniques on encrypted data.
If your application requires a secure iSCSI transport between the ESXi host and the Blockbridge dataplane, please contact Blockbridge support.
(Encryption is a relatively new feature, introduced in vSphere 6.5.)
Zeroing Policies
VMware famously has three types of guest disks: Thin, Lazy Zeroed, and Eager Zeroed. With a Blockbridge array, Thin disks are nearly always the right choice.
There are three factors at play in our recommendation:
-
Blockbridge doesn’t allocate storage for zeroes. VMware uses VAAI zeroing commands (SCSI WRITE SAME) for the two Zeroed disk types. If the regions of disk it’s zeroing are not allocated, Blockbridge doesn’t bother allocating the storage. It’s already zeroed.
-
VMware has its own VMFS metadata to allocate. Though these operations are fast, it’s a consideration. VMFS has to track the block allocations, so doing Eager Zeroed would get these all out of the way up front.
-
Lazy Zeroed disks zero the storage, then write it. The write is serialized behind the zeroing operation. Instead of simply sending the write along to the Blockbridge LUN, where it can allocate storage optimally, it takes an additional round trip to allocate storage first before it can be written. Sure, the zeroing is very fast, but it’s still additional latency. This is typically slower than the Thin disk performance, where you “just write it”.
Blocks on Thin disks are always allocated on demand. There’s no zeroing done ahead of time, or even just-in-time. In most cases, this is preferable. They don’t take up space that they don’t need, and they don’t have the write serialization penalty of Lazy Zeroed disks.
Guest I/O Latency & Consistency
Achieving the lowest possible latency inside a guest requires dedicating CPU resources to it. For example, to dedicate a CPU core to a guest:
-
Select “High” Latency Sensitivity:
-
Add a CPU frequency Reservation for the full frequency of the CPU:
-
Set the Scheduling Affinity to a CPU core that has not been dedicated to another VM: